承寶(참참)
2007. 12. 5. 00:02
2007. 12. 5. 00:02
Matrix Multiplication은 상당히 잦은 연산중에 하나다.
이 연산의 효율은 상당히 떨어진다.
이 연산을 빠르게 할수만 있다면 얼마나 많은 프로그램에서 보다 빠르게 프로그램을 구동할 수 있을까?
빠르게 하려면 어떻게 해야 좋을까?
놀고 있는 그래픽 카드를 써보자.
그래서 유로그래픽스에 발표된 논문이 바로 Matrix Multiplication이란 논문이다.
수업시간에 과제를 겸해서 이걸 간단하게 이 논문 내용을 구현해 보기로 했다.
미리 말하지만.. 3x3, 4x4 행렬의 곱을 말하는 게 아니다.
Dense Matrix..
즉, 데땅 큰 행렬만 취급한다.
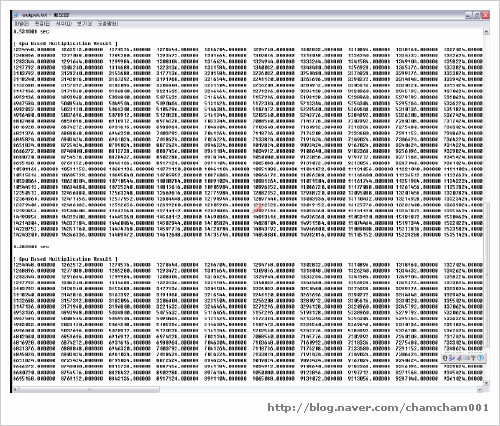
실험은 32x32부터 1024x1024까지 해봤다.
그래픽 카드는 Geforce 6200, 6800에서 해봤고..
최근에 7900에서 해봤다.
결과적으로 빠르다.
아니 빨라야 정상이다.
하지만, 6200의 경우 Dense한 정도가 낮으니 오히려 느려졌다.
물론 논문에서 처럼 수학전문 라이브러리를 쓴건 아니지만...
여튼.. 그런 cpu 알고리즘 보다 늦었다.
이유는.. 그래픽카드에서 메인 메모리로 넘겨주는 버스 속력이 느리기 때문에..
하지만 매트릭스가 dense할 수록..
cpu는 급격히 느려지는 반면..
gpu는 그 느려짐이 완만해 졌다.
즉, gpu내부의 연산 능력은 훨씬 빠르다는 뜻..
최근의 7900에서 테스트 결과..
버스 스피드도 많이 개선되었고.. gpu 자체의 속력도 엄청나게 올라갔다.
그래서..
훨~~씬 빠른 계산 능력을 보여줬다.
그럼 결론은 여기까지 하고..
그럼 어케 그림 그리는 그래픽 카드로 계산을 하느냐..
그래픽 파이프 라인안에 우린 손을 델 수 있으니까..
제한적이긴 하지만..
shading language로 fragment 부분을 프로그래밍 해주면 된다.
물론 데이터는 texture에 넣어서 넘겨주고..
그렇게 텍스쳐에 n x n 행렬을 넣어주고
그걸 읽어와서..
계산을 해주면 그래픽 카드는 병렬처리하니까.. 더 빠르게 계산될테고..
처리해서 다시 graphic buffer에 써주면 된다.
그 buffer에서 다시 데이터를 읽고 그걸 출력하면 끝..
이때 graphic buffer에서 데이터를 읽을때 무진장 긴 시간을 소비한다.
여기서 bottle neck 발생..
여튼 아직 공부도 더 필요하고 개선될 여지도 많은..
재미있는 분야..
다만.. 뭔가 다른 주제 하나를 가지고 있어야..
이걸 응용하는 것이 가능할듯..
기존에 했던 작업을 이걸로 더 개선한다거나 하는..
언젠간 공부한거 써 먹겠지..
교수님 말 안듣고.. 혼자 심심해서 해봤던 공부..
음.. 덕분에 많이 손해봤지만.. 그래도.. 나름 재미있었는데.. ㅋ